![[新機能]Iceberg tablesに対してADD_FILES_COPYオプションでロードすることで元のparquetをそのままS3内でコピーして高速にロードできるようになりました](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-37f4322e7cca0bb66380be0a31ceace4/0886455fd66594d3e7d8947c9c7c844d/eyecatch_snowflake?w=3840&fm=webp)
[新機能]Iceberg tablesに対してADD_FILES_COPYオプションでロードすることで元のparquetをそのままS3内でコピーして高速にロードできるようになりました
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
さがらです。
先月、Iceberg tablesへのCOPY INTO及びSnowpipeが一般提供となりました。
これに加えて、新しいLOAD_MODEオプションとしてADD_FILES_COPYが追加されました。こちらのオプションについては公式ドキュメントも更新されています。
ADD_FILES_COPY: Loads data from Iceberg-compatible Parquet data files by performing a server-side copy of the files into the table’s base location and fast registering the files to the table.
このADD_FILES_COPYオプションを試してみたので、本記事でまとめてみます。
やること
まず、S3上のバケットに下図のようにparquet形式でデータがあるとします。元のデータはsnowflake_sample_data.tpcds_sf10tcl.customerテーブルのデータであり、18列6500万行のデータとなっています。
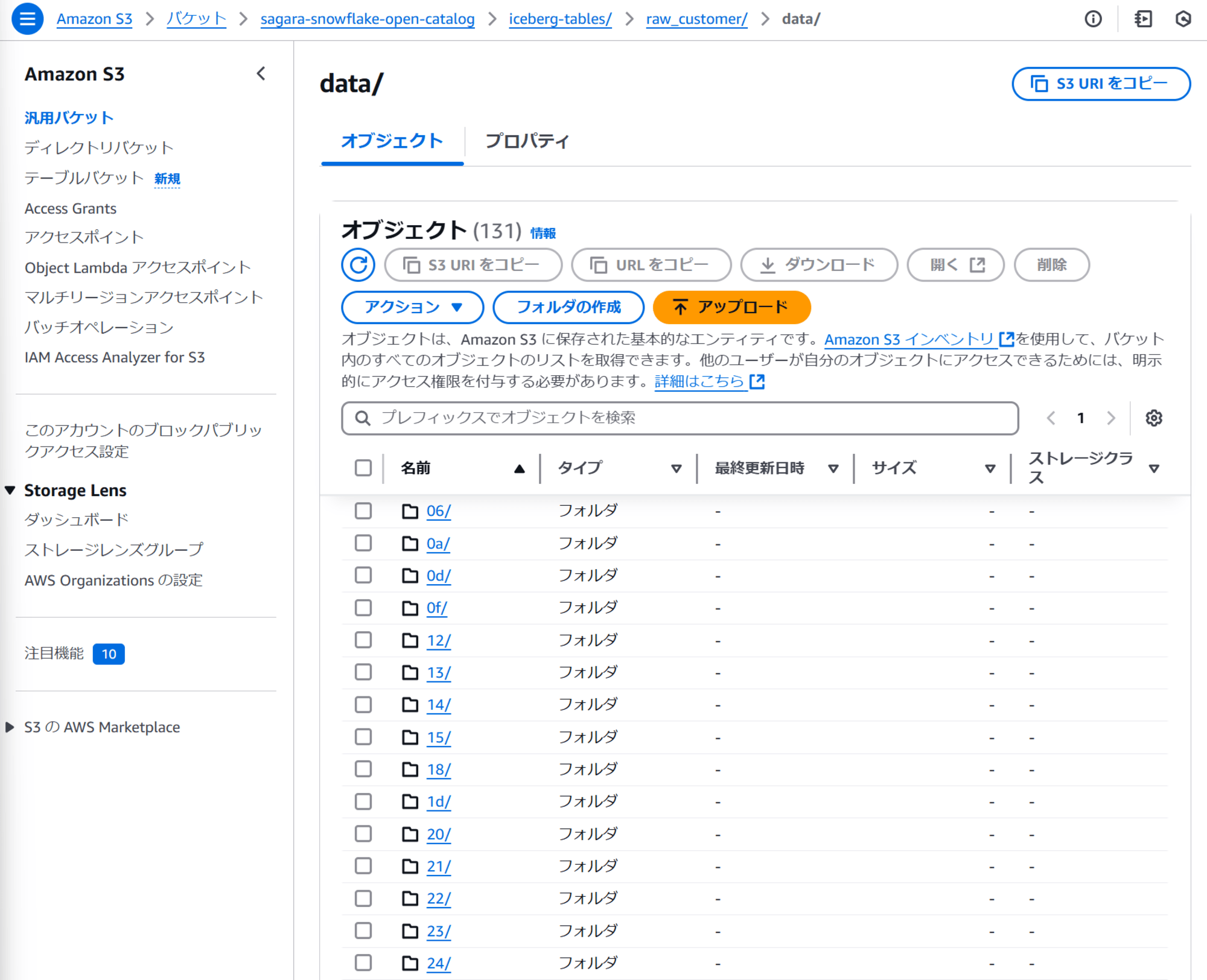
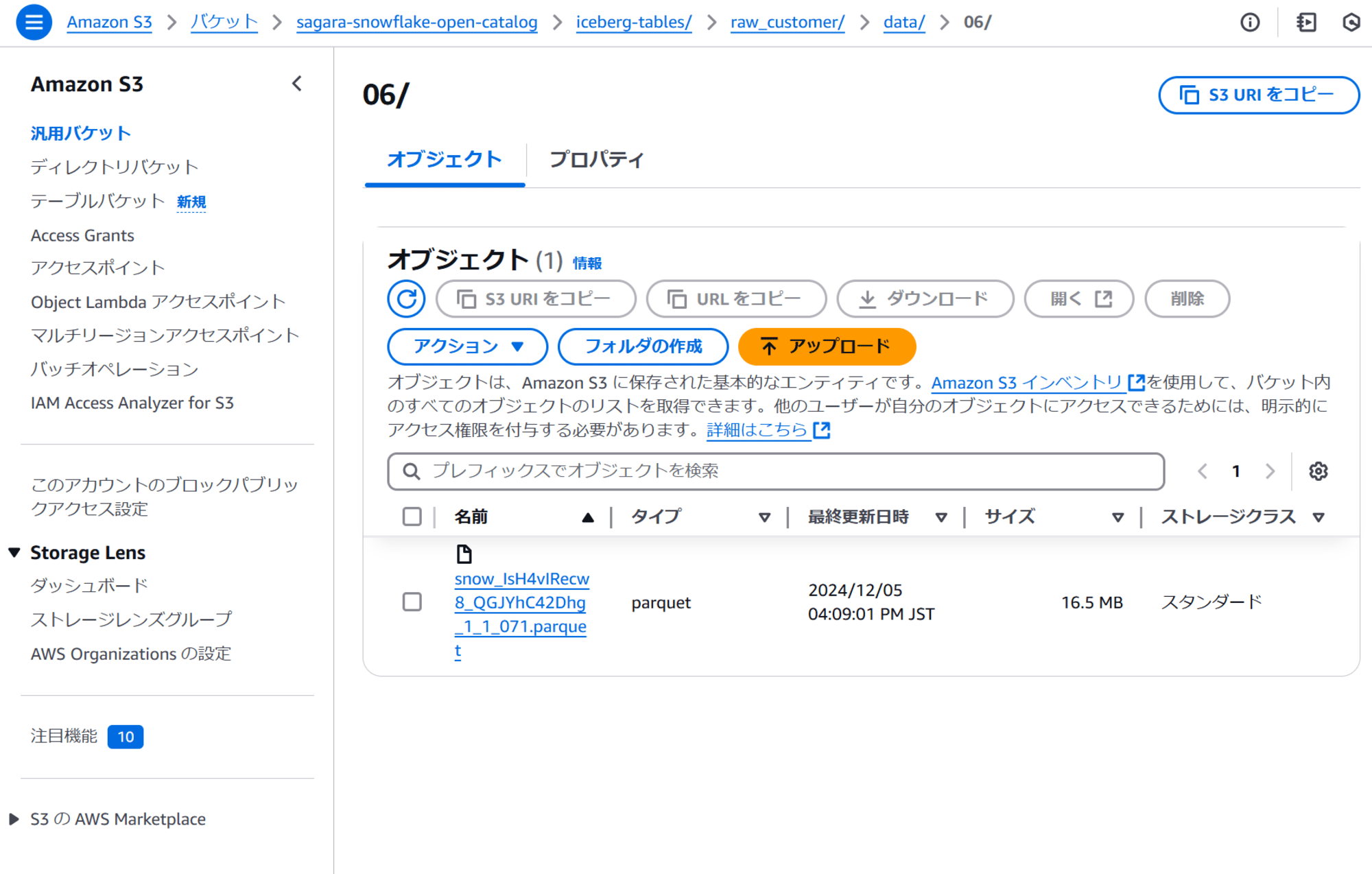
このparquetファイルを、LOAD_MODE = FULL_INGESTとLOAD_MODE = ADD_FILES_COPYの2つの方法でロードしてみて、どのような違いが出るかを確認してみます。
事前準備
まず、使用するカタログはSnowflake Open Catalogです。(下記の記事で検証した際に作成したカタログをそのまま使用します。)
この上で、どちらのパターンでも利用するファイルフォーマットと外部ステージを下記のクエリで定義しておきます。(Storage Integrationの定義は省略します。)
create or replace file format sagara_parquet_format
type = parquet
use_vectorized_scanner = true;
create stage sagara_s3_open_catalog_stage
storage_integration = sagara_s3_open_catalog_int
url = 's3://sagara-snowflake-open-catalog/iceberg-tables/'
file_format = sagara_parquet_format;
パターン1:LOAD_MODE = FULL_INGESTでロード
まず、LOAD_MODE = FULL_INGESTでロードしてみます。(ウェアハウスのサイズはXSで、クラスタ数は1です。)
create or replace iceberg table customer_full_ingest (
c_birth_country varchar,
c_birth_day varchar,
c_birth_month varchar,
c_birth_year varchar,
c_current_addr_sk varchar,
c_current_cdemo_sk varchar,
c_current_hdemo_sk varchar,
c_customer_id varchar,
c_customer_sk varchar,
c_email_address varchar,
c_first_name varchar,
c_first_sales_date_sk varchar,
c_first_shipto_date_sk varchar,
c_last_name varchar,
c_last_review_date varchar,
c_login varchar,
c_preferred_cust_flag varchar,
c_salutation varchar
)
catalog = 'snowflake'
external_volume = 'sagara_iceberg_external_volume'
base_location = 'customer_full_ingest'
catalog_sync = 'sagara_open_catalog_int';
copy into customer_full_ingest
from @sagara_s3_open_catalog_stage/raw_customer/data
load_mode = full_ingest
match_by_column_name = case_sensitive;
こちらのパターンだと、データロードに1分42秒かかりました。
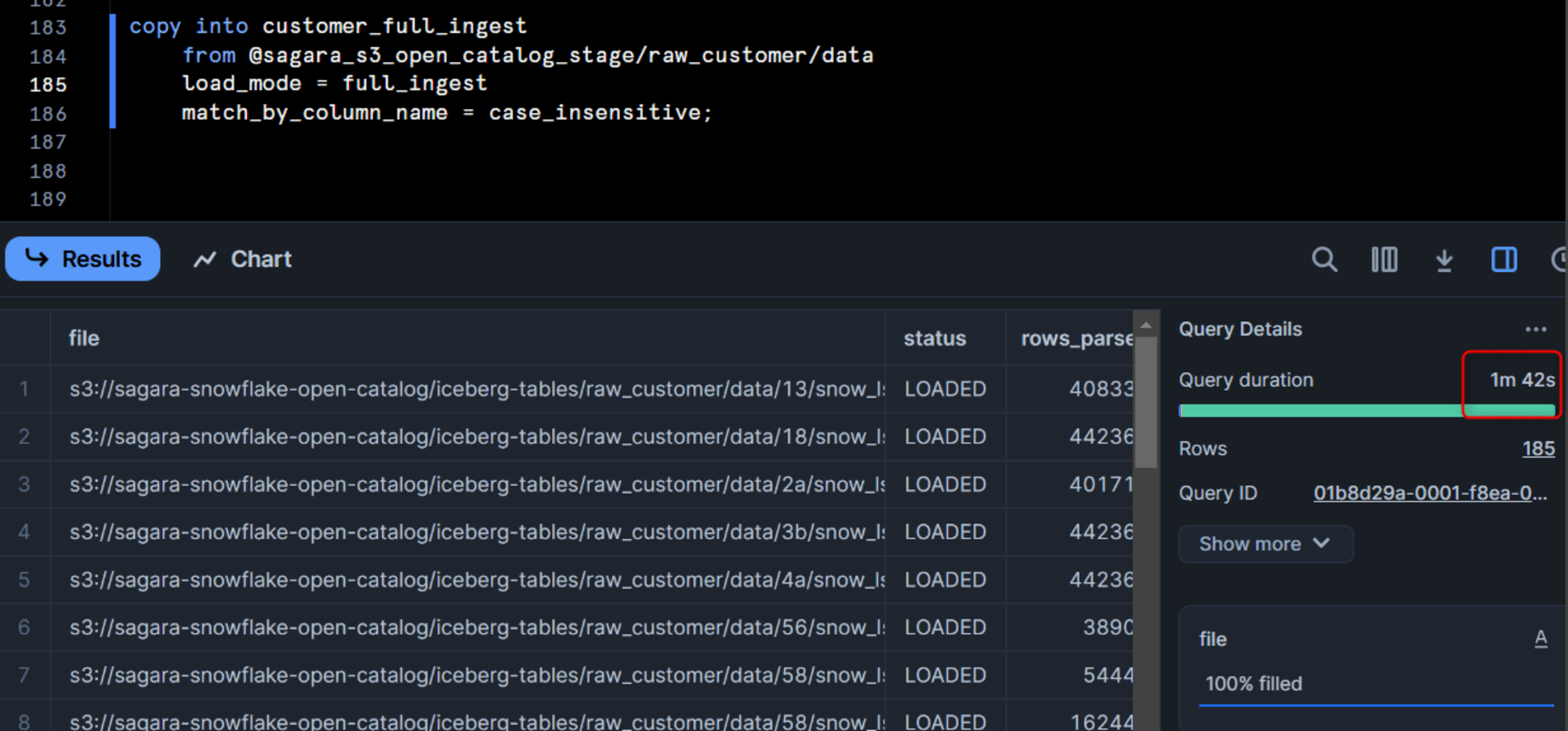
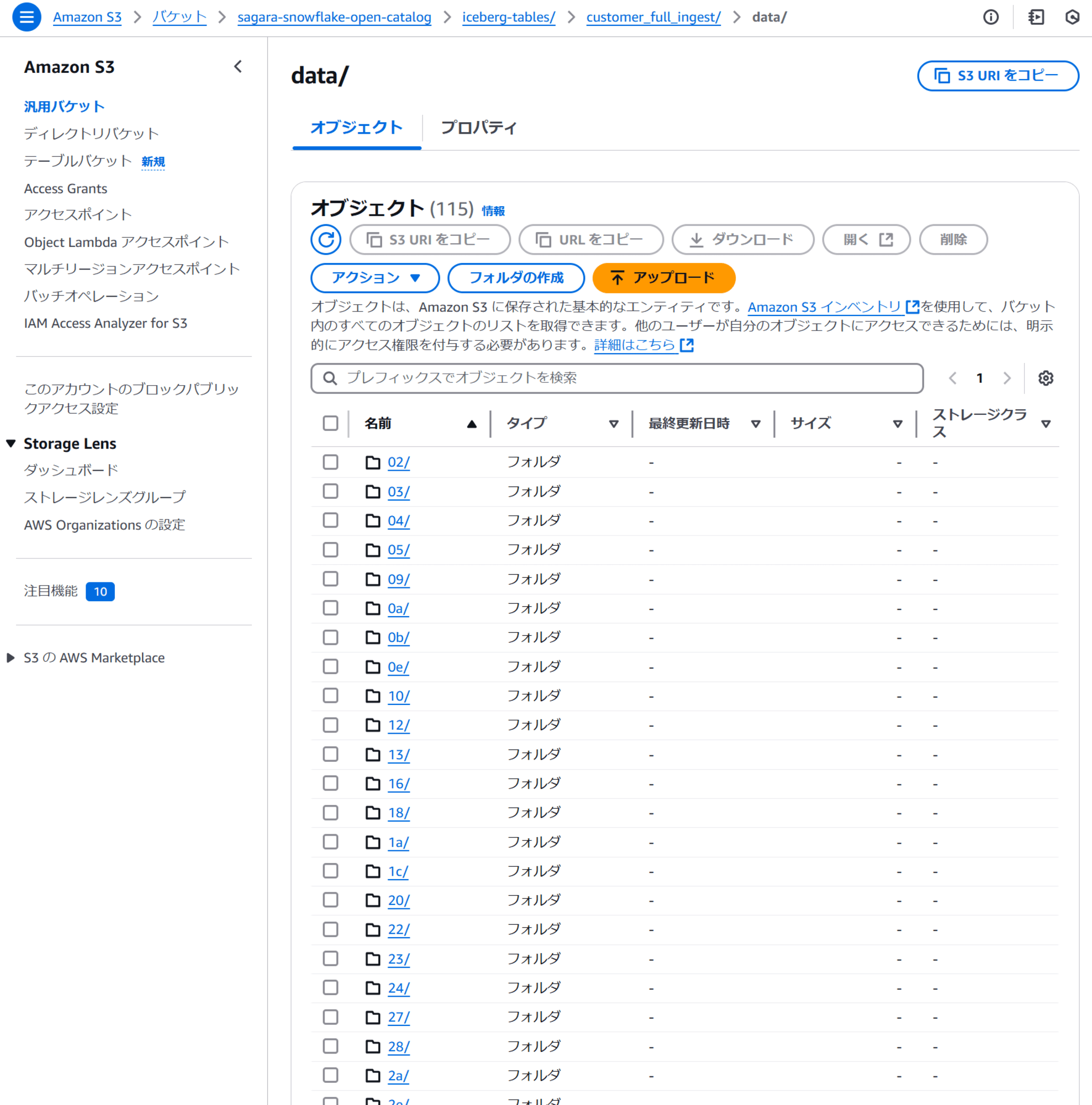
また、「ロード元のS3フォルダ」と「ロード先のS3フォルダ」を比較すると、dataフォルダのサブフォルダ構成が全く異なっていることがわかります。
これは、LOAD_MODE = FULL_INGESTの場合だと、「ロード元のS3フォルダ」のparquetをSnowflakeでスキャン→「ロード先のS3フォルダ」にparquetを新しく作りながらロード処理という形でロードを行っているためです。そのためロードにはどうしても時間がかかってしまいます。
- ロード元のS3フォルダ
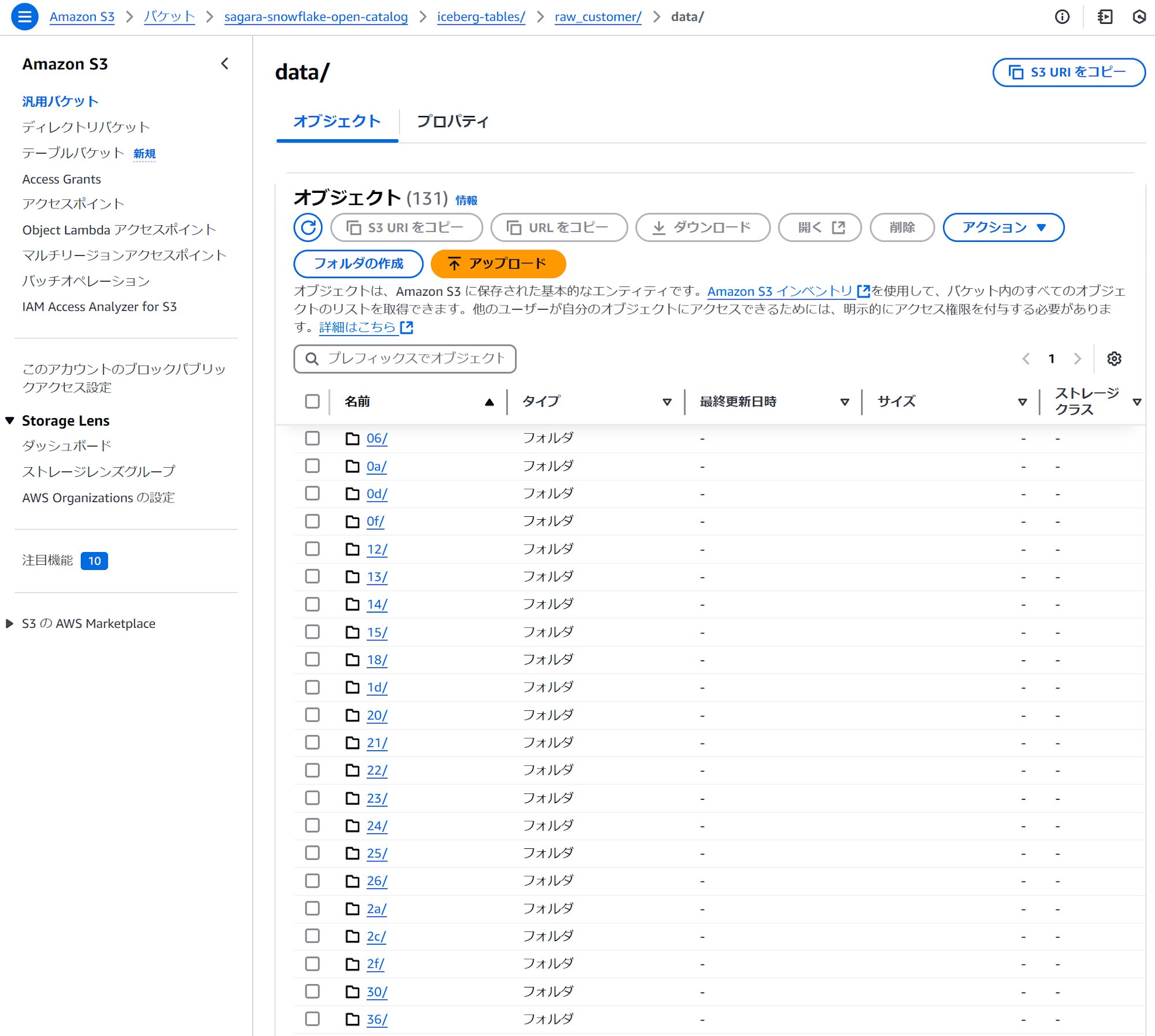
- ロード先のS3フォルダ
パターン2:LOAD_MODE = ADD_FILES_COPYでロード
次に、LOAD_MODE = ADD_FILES_COPYでロードしてみます。(ウェアハウスのサイズはXSで、クラスタ数は1です。)
create or replace iceberg table customer_add_files_copy (
c_birth_country varchar,
c_birth_day varchar,
c_birth_month varchar,
c_birth_year varchar,
c_current_addr_sk varchar,
c_current_cdemo_sk varchar,
c_current_hdemo_sk varchar,
c_customer_id varchar,
c_customer_sk varchar,
c_email_address varchar,
c_first_name varchar,
c_first_sales_date_sk varchar,
c_first_shipto_date_sk varchar,
c_last_name varchar,
c_last_review_date varchar,
c_login varchar,
c_preferred_cust_flag varchar,
c_salutation varchar
)
catalog = 'snowflake'
external_volume = 'sagara_iceberg_external_volume'
base_location = 'customer_add_files_copy'
catalog_sync = 'sagara_open_catalog_int';
copy into customer_add_files_copy
from @sagara_s3_open_catalog_stage/raw_customer/data
load_mode = add_files_copy
match_by_column_name = case_sensitive;
こちらのパターンだと、データロードに14秒かかりました。明らかにLOAD_MODE = ADD_FILES_COPYの方が早いですね!
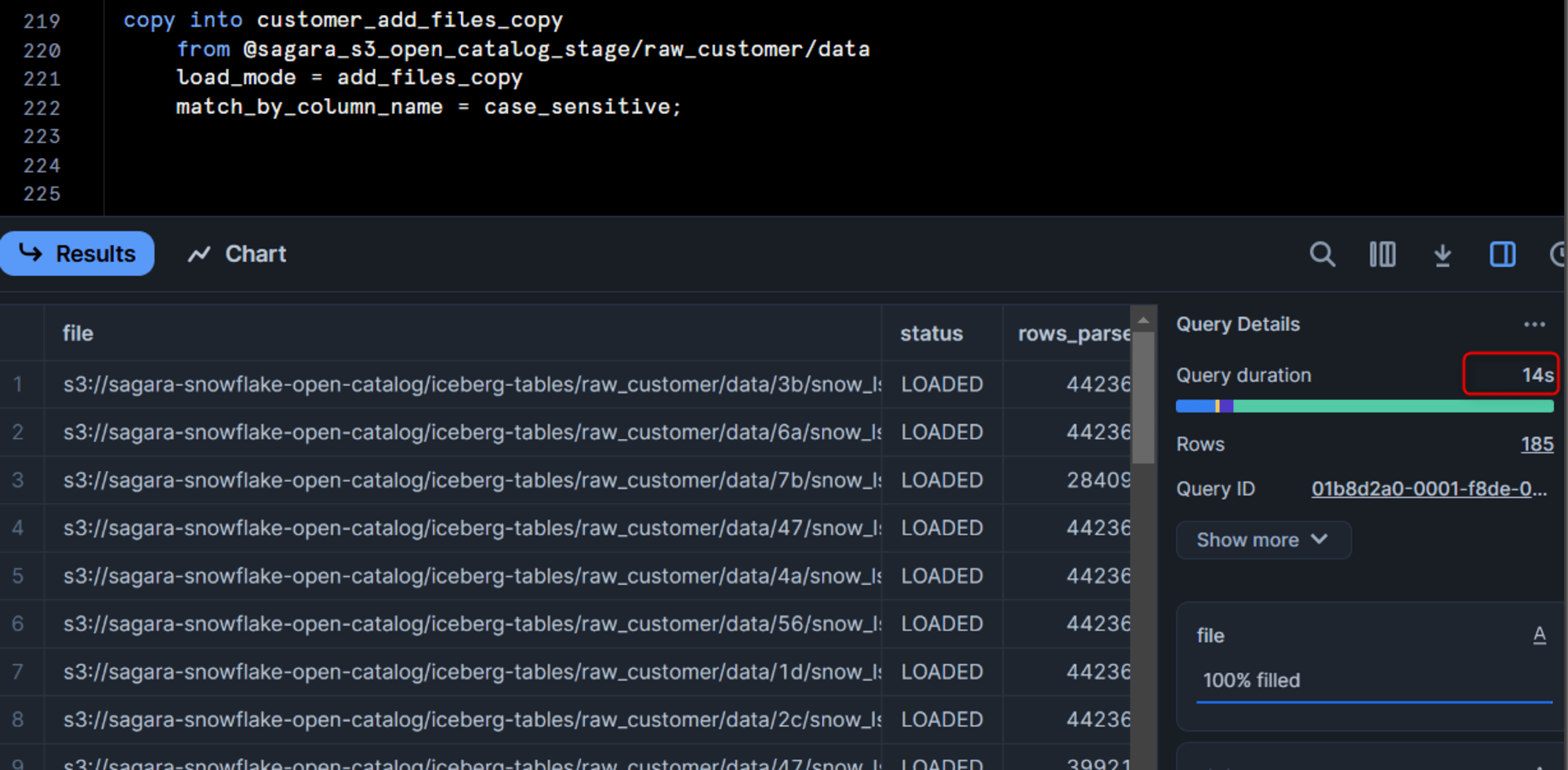
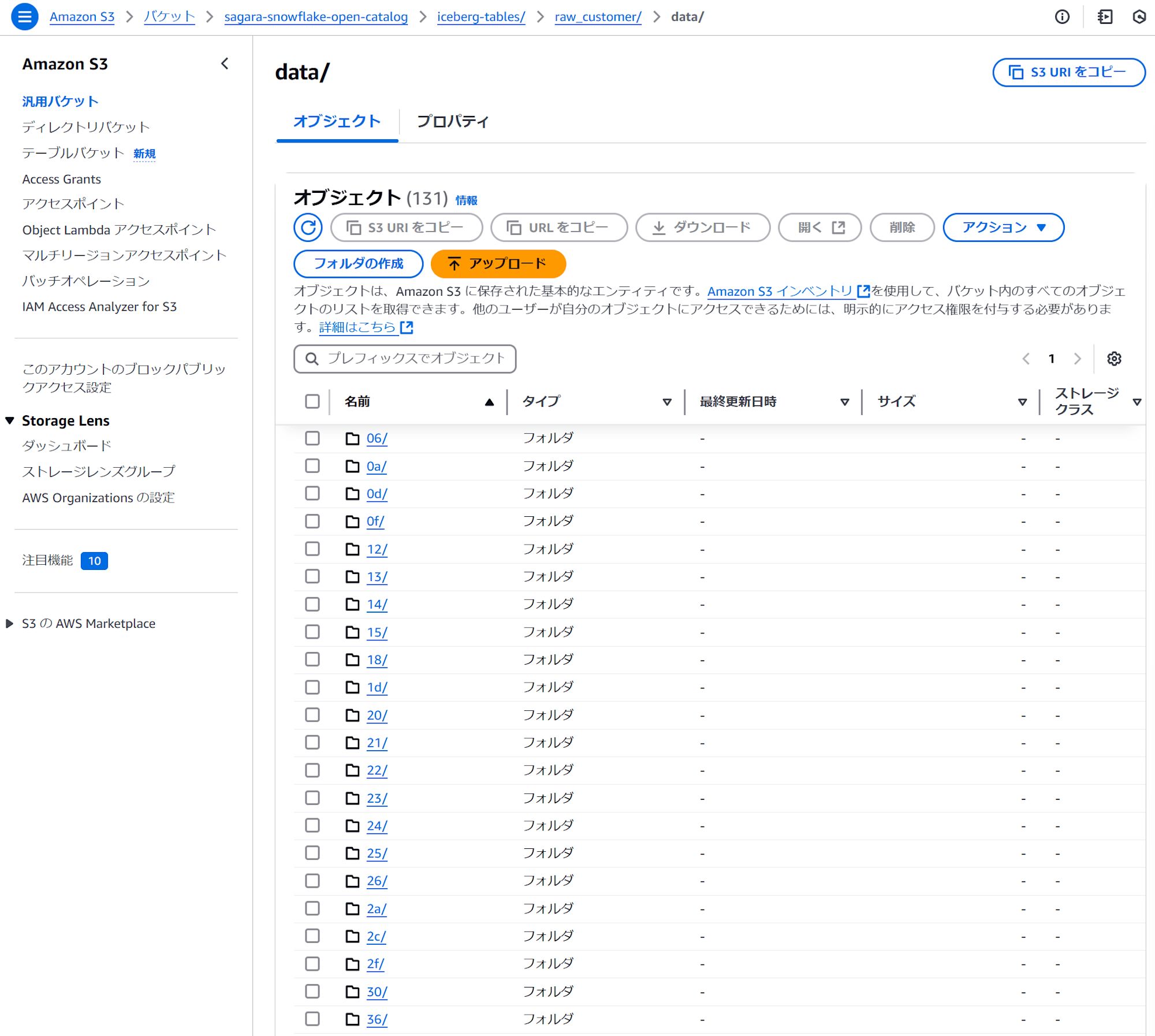
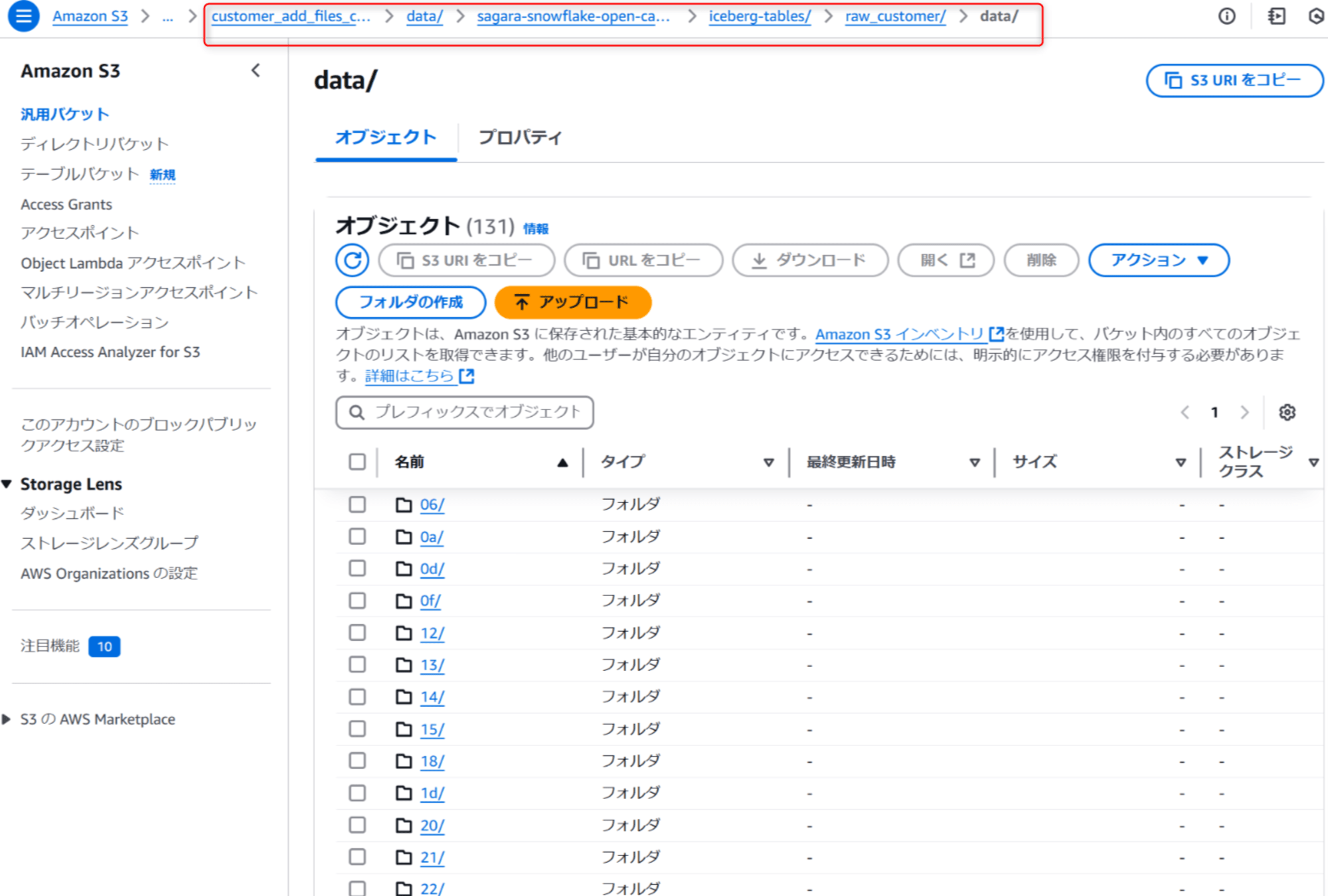
また、「ロード元のS3フォルダ」と「ロード先のS3フォルダ」を比較すると、「ロード先のS3フォルダ」のdataフォルダのサブフォルダに「ロード元のS3フォルダ」がそのままコピーされる形となっています。(ルートのフォルダからコピーされる形になっています。)
これは、LOAD_MODE = ADD_FILES_COPYの場合だと、「ロード元のS3フォルダ」のparquetを「ロード先のS3フォルダ」にそのままコピー→「ロード先のS3フォルダ」にコピーされたparquetをそのままIceberg tablesとして扱うという形でロード処理を行っているためです。そのためSnowflakeからS3へのスキャンとparquetの生成が発生せず、高速にロード処理を行うことが出来ています。
- ロード元のS3フォルダ
- ロード先のS3フォルダ
おまけ:LOAD_MODE = ADD_FILES_COPYでbase_locationに「ロード元のS3フォルダ」を指定してロード
私がまだIceberg tablesに慣れていないこともあるので、LOAD_MODE = ADD_FILES_COPYでロードにしたうえで、Iceberg tablesを作るときのbase_locationオプションに「ロード元のS3フォルダ」を指定してロードすると、どのような挙動となるか試してみました。
※base_locationオプションに指定した名称で、S3バケットにフォルダが作られる仕様となっています。
create or replace iceberg table customer_add_files_copy_with_same_location (
c_birth_country varchar,
c_birth_day varchar,
c_birth_month varchar,
c_birth_year varchar,
c_current_addr_sk varchar,
c_current_cdemo_sk varchar,
c_current_hdemo_sk varchar,
c_customer_id varchar,
c_customer_sk varchar,
c_email_address varchar,
c_first_name varchar,
c_first_sales_date_sk varchar,
c_first_shipto_date_sk varchar,
c_last_name varchar,
c_last_review_date varchar,
c_login varchar,
c_preferred_cust_flag varchar,
c_salutation varchar
)
catalog = 'snowflake'
external_volume = 'sagara_iceberg_external_volume'
base_location = 'raw_customer'
catalog_sync = 'sagara_open_catalog_int';
copy into customer_add_files_copy_with_same_location
from @sagara_s3_open_catalog_stage/raw_customer/data
load_mode = add_files_copy
match_by_column_name = case_sensitive;
このパターンだと、データロードに7.8秒かかりました。(なぜロードが速くなったのか気になってテーブルを再定義しロードを2回行ったのですが、2回目は8秒でした。)
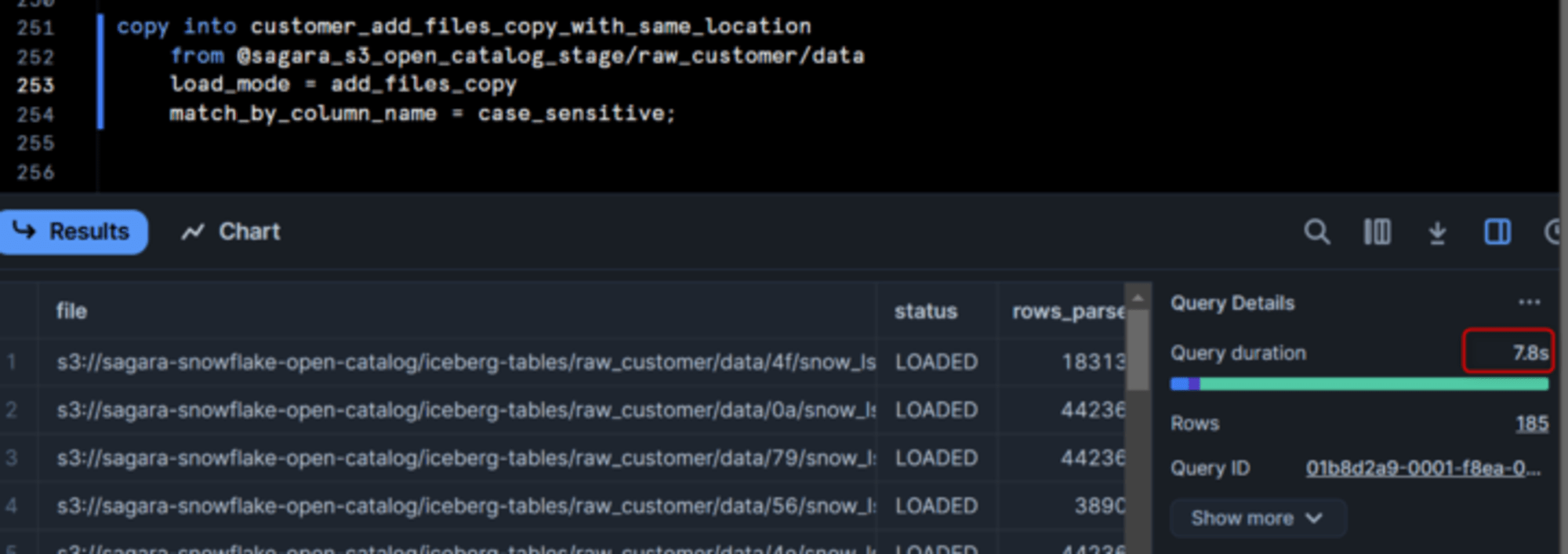
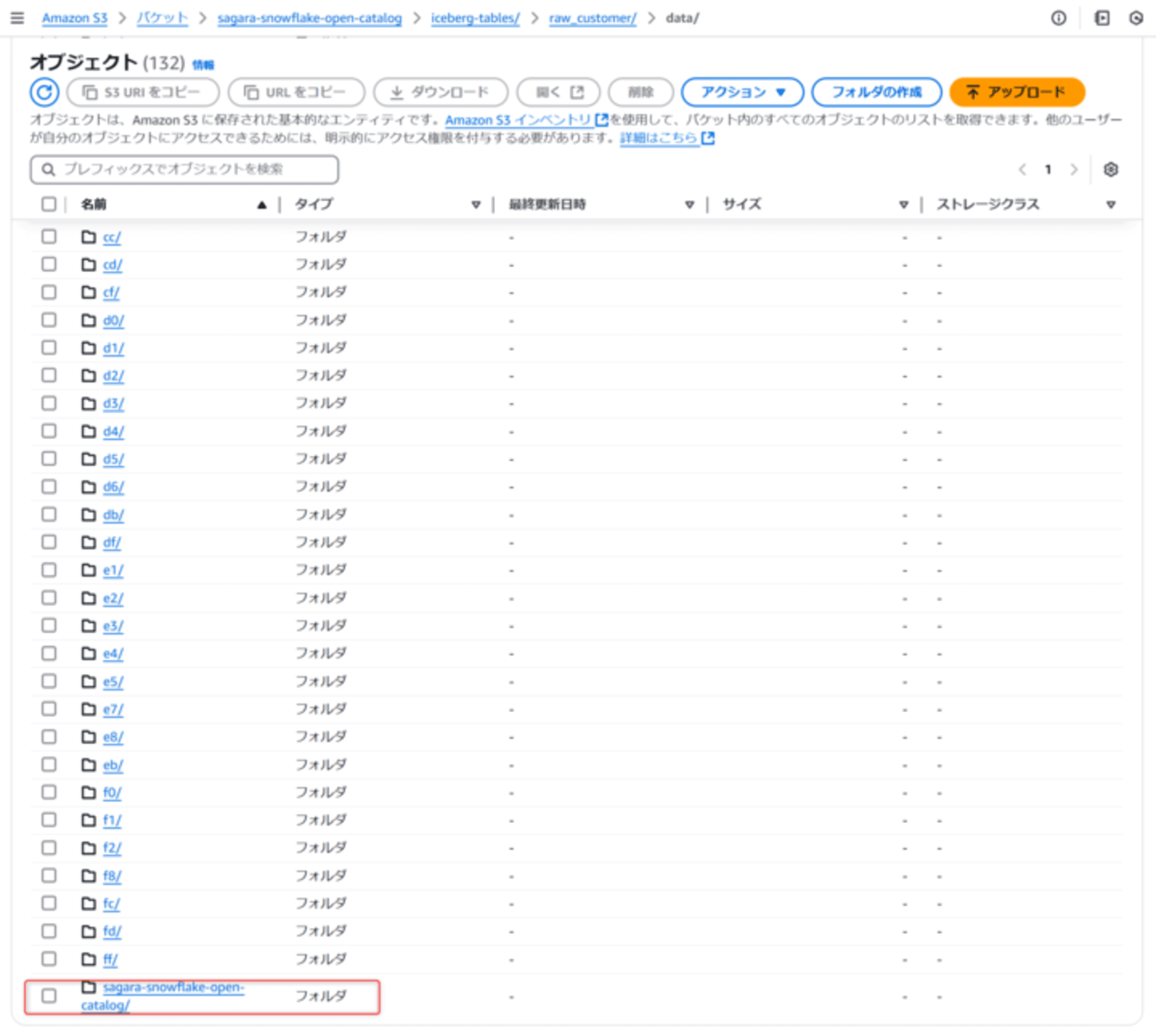
この上でS3を確認すると、「ロード元のS3フォルダ」の中に、「ロード元のS3フォルダ」がルートからそのままコピーされる形となっていました。(コピーが発生しないのでは、という淡い期待を抱いていたのですが、そんなことはなかったですねw)
最後に
Iceberg tablesへのCOPY INTOのオプションとしてADD_FILES_COPYが追加されたので、試してみました。
想像以上にparquetファイルのロードが速くなった点は素晴らしいなと感じました!一方でルートフォルダからコピーするためフォルダ階層がかなり深くなってしまうことは気になりました、ルートからコピーしてしまう仕様だけもう少し良くならないかな、と今後に期待しています!







